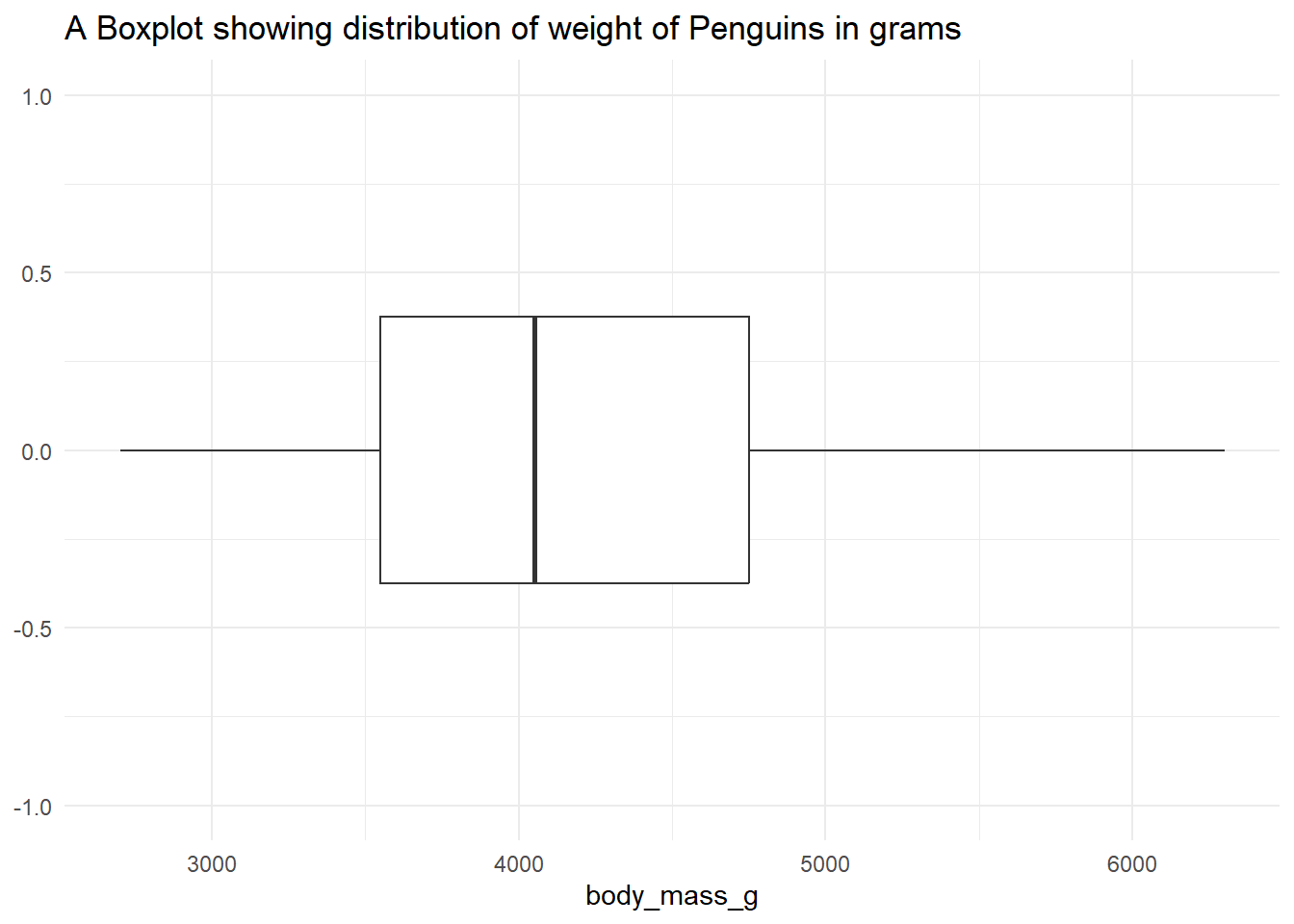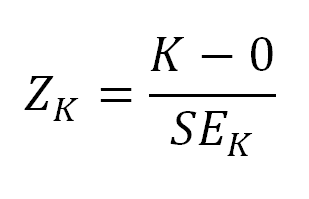Data summarization is an essential process in statistical programming, which involves reducing and simplifying large datasets into more manageable and understandable forms. This process is crucial as it helps in highlighting the key aspects of the data by extracting important patterns, trends, and relationship. In the realm of statistical analysis, summarization is not just about making the data smaller or simpler, it is about capturing the essence of the data in a way that is both informative and useful for analysis.
Types of Summarization Techniques
Numerical Summarization: This involves using statistical measures to summarize the key characteristics of numerical data. Techniques include calculating measures of central tendency (like mean, median, and mode) and measures of variability or spread (like range, variance, and standard deviation). These techniques are fundamental in providing a quick snapshot of the data’s overall distribution and central values.
Categorical Summarization: When dealing with categorical (or qualitative) data, summarization often involves understanding the frequency or occurrence of different categories. Techniques include creating frequency tables, cross-tabulations, and using measures like mode. This type of summarization is particularly useful in understanding the distribution of categorical variables, like customer categories or product types.
Visual Summarization: Visual representations of data, such as histograms, bar charts, box plots, and scatter plots, provide an intuitive way to summarize and understand complex datasets. These techniques are invaluable in revealing patterns, trends, outliers, and relationships in data that might not be obvious in textual or numerical summaries.
In R, these summarization techniques are supported by a variety of functions and packages, making it an ideal environment for both basic and advanced data summarization tasks. This chapter will delve into these techniques, providing the reader with the knowledge and tools to effectively summarize and interpret large datasets using R.
Summarizing Numerical Data
Introduction to Normality Testing.
Normality testing is a fundamental step in statistical analysis, particularly when deciding which statistical methods to apply. Many statistical techniques assume that the data follows a normal (or Gaussian) distribution. However, real-world data often deviates from this idealized distribution. Therefore, assessing the normality of your dataset is crucial before applying techniques that assume normality, such as parametric tests.
In R, there are several methods to test for normality, including graphical methods like Q-Q plots and statistical tests like the Shapiro-Wilk test. Let’s explore how to perform these tests in R with an example dataset.
Graphical Methods to Identify Normality distribution
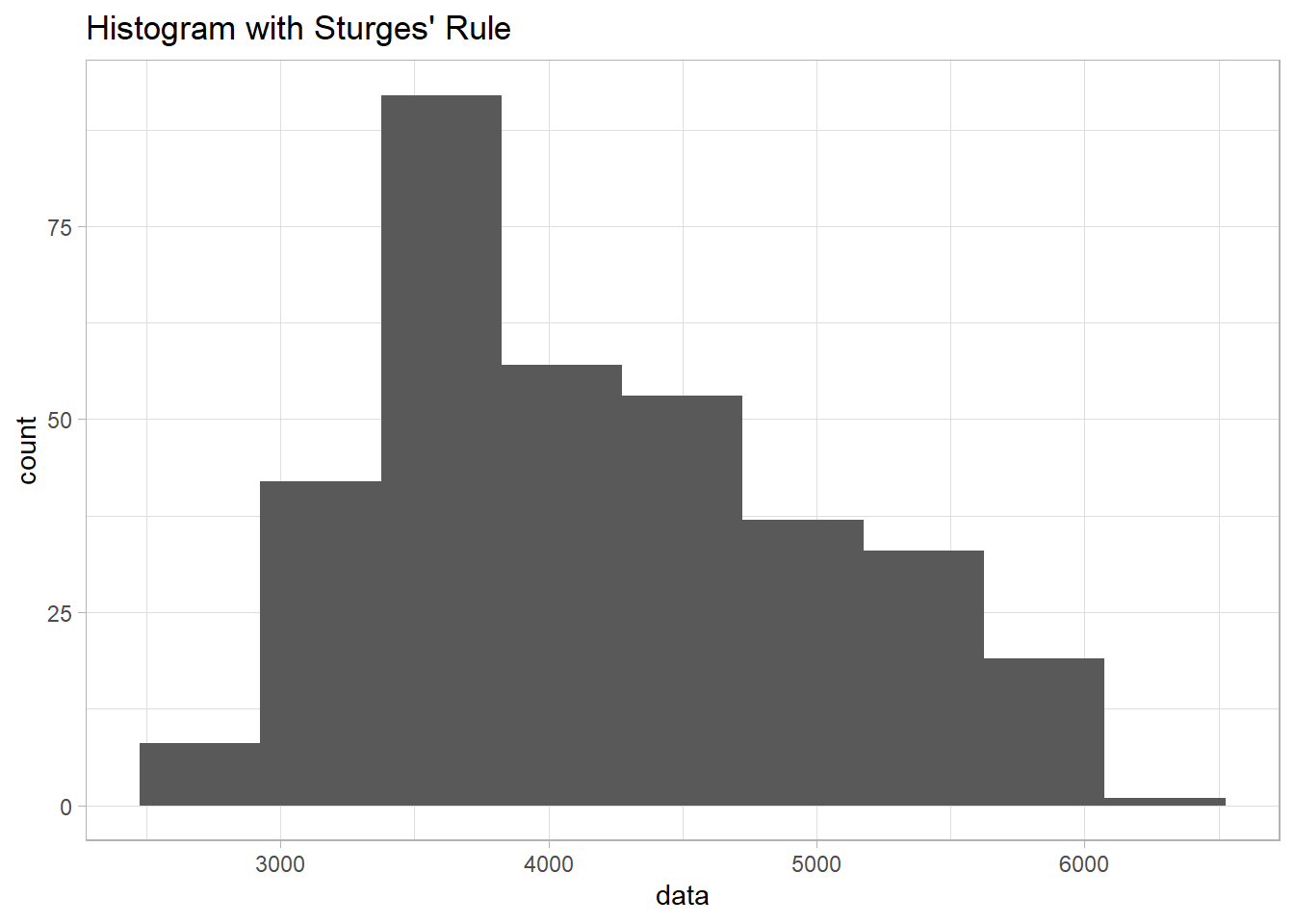
1) Histogram
library(palmerpenguins)library(ggplot2)data <-na.omit(penguins$body_mass_g) # Remove NA valuesnum_bins_sturges <-1+log2(length(data)) #calculating number of bins using struge's rulesggplot(data.frame(data), aes(x = data)) +geom_histogram(bins =round(num_bins_sturges)) +ggtitle("Histogram with Sturges' Rule") +theme_light()
2) Boxplot
ggplot(penguins, aes(body_mass_g)) +geom_boxplot() +ggtitle("A Boxplot showing distribution of weight of Penguins in grams") +theme_minimal() +scale_y_continuous(limits=c(-1,1))
Based on the boxplot, we can clearly see that the data was a bit skewed to the right.
3) Kurtosis and Skewness
Kurtosis is a measure of a sample or population that identifies how flat or peaked it is with respect to a normal distribution. It refers to how concentrated the values are in the center of the distribution. In other hand, sample can be described as a measure of horizontal symmetry with respect to a normal distribution by measuring the skewness coefficient. If the coefficient of skewness can be either positive (right skew), zero (no skew), or negative (left skew).
Steps examining sample normality by skewness and kurtosis:
1) Determine sample mean and standard deviation
2) Determine sample kurtosis and skewness
Formula Skewness:
Formula for Standard Error of Skewness:
Formula Kurtosis:
Formula for Standard Error of Kurtosis:
3) Calculate the standard error of the kurtosis and the standard error of the skewness
4) Calculate Z-Score for the kurtosis and Z-Score for the skewness
Formula for Z-Score Skewness:
Formula for Z-Score Kurtosis:
5) Compare the Z-Score to the critical region obtained from the normal distribution
The Z-score is to examine the sample’s approximation to a normal distribution.
Z-score values for kurtosis and skewness must fall between -2 and 2 to pass the normality assumption for alpha=0.05.
Z-score for Skewness: This score indicates how many standard deviations the skewness of the dataset is from the mean skewness of a normally distributed dataset. A higher absolute value of the z-score indicates a greater degree of asymmetry.
Z-score for Kurtosis: Similarly, this score tells us how many standard deviations the kurtosis of the dataset is from the mean kurtosis of a normal distribution. It reflects the “tailedness” or the peak height of the distribution.
Z-score between -2 and 2: This range is generally considered to indicate that the skewness or kurtosis is not significantly different from what would be expected in a normal distribution. The data can be considered approximately normal in this aspect.
Z-score less than -2: This suggests a significant deviation from normality in a negative direction. For skewness, it would mean a left skew (tail is on the left side). For kurtosis, it indicates a platykurtic distribution (less peaked than a normal distribution).
Z-score greater than 2: This indicates a significant deviation in a positive direction. For skewness, it would imply a right skew (tail is on the right side). For kurtosis, it suggests a leptokurtic distribution (more peaked than a normal distribution).
It is clearly seen that the value of Z-Score for skewness is beyond 2, which indicating the data is skewed to the right tail. and the value of Z-Score for kurtosis is less than -2, indicating platykurtic distribution (less peaked than a normal distribution).
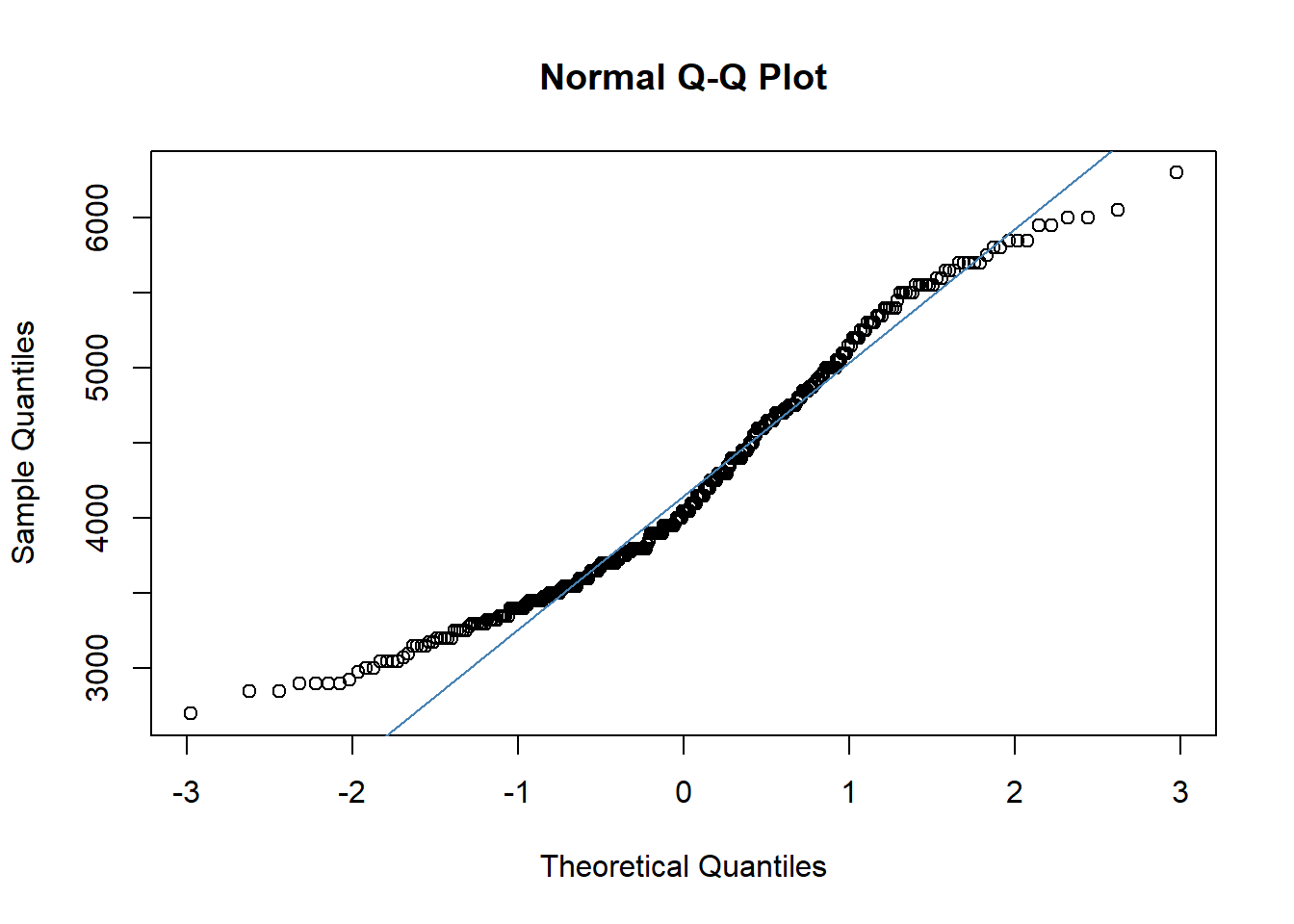
4) Q-Q plots
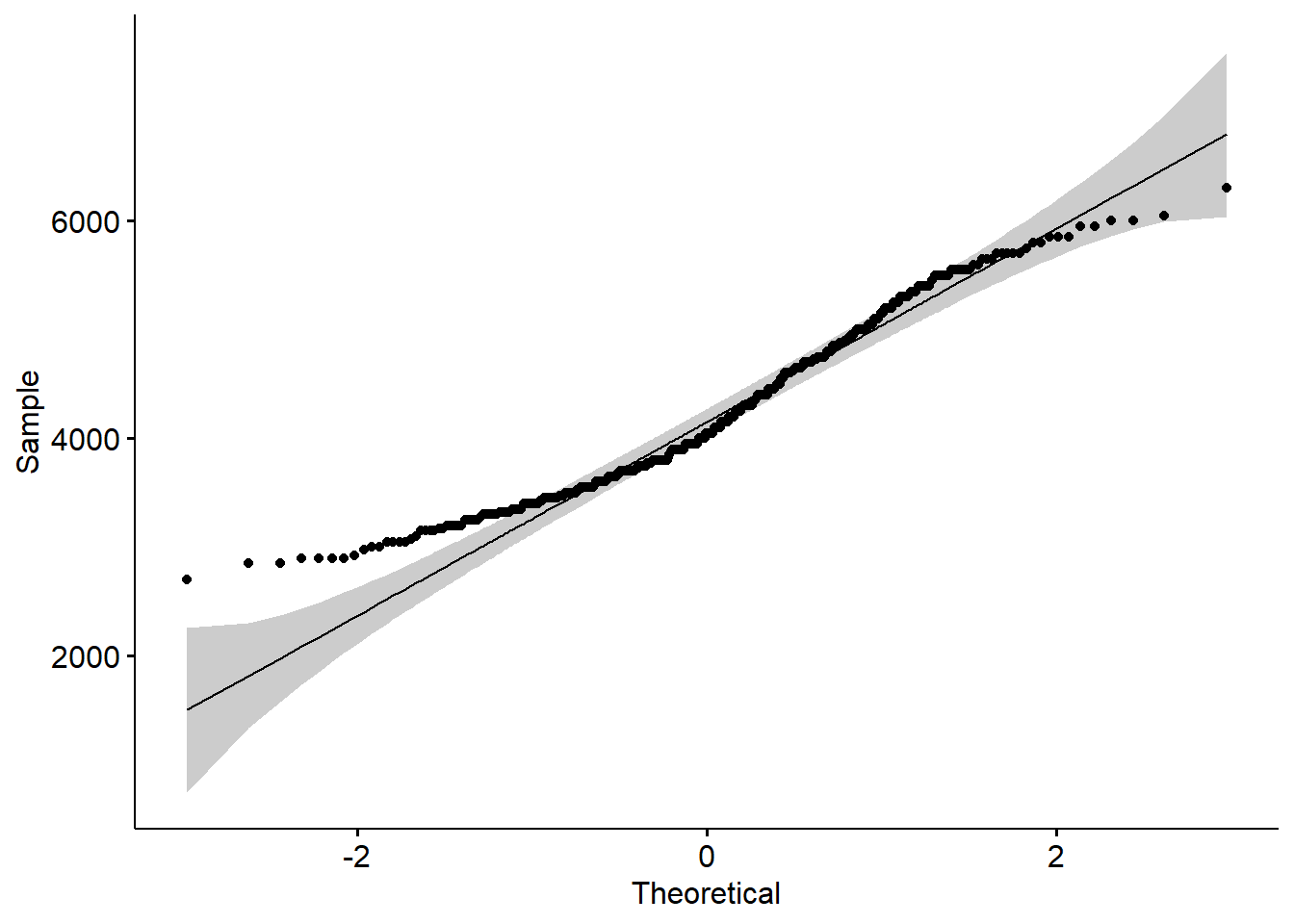
Q-Q plots are scatterplots created by plotting two sets of quantiles against each other: the quantiles from the dataset and the quantiles of a normal distribution. If the data are normally distributed, the points in the Q-Q plot will approximately lie on a straight line.
Interpreting the Q-Q Plot
Linearity: In a Q-Q plot, if the data are normally distributed, the points will approximately lie on a straight line. The closer the points are to the line (qqline), the more normal the distribution is.
Departures from Linearity: Deviations from the line can indicate departures from normality:
Left Tail (lower end of the plot): If the points deviate below the line at the lower end, it suggests a left-skewed distribution (lighter left tail than normal).
Right Tail (upper end of the plot): If the points deviate above the line at the upper end, it indicates a right-skewed distribution (heavier right tail than normal).
Center of the Plot: If the points deviate from the line in the middle of the plot, it suggests a difference in the median or a distribution with different kurtosis from normal (either more peaked or flatter than a normal distribution).
#Create Q-Q plotqqnorm(penguins$body_mass_g)#Adding straight diagonal line to plotqqline(penguins$body_mass_g)qqline(penguins$body_mass_g,main ='Q-Q Plot for Normality', xlab ='Theoretical Dist', ylab ='Sample dist', col ='steelblue')
Another way to construct qqplot
library(ggpubr)ggqqplot(penguins$body_mass_g)
By examining how the points in the Q-Q plot deviate from the reference line, we can infer if and how the body_mass_g distribution deviates from a normal distribution. Remember, a Q-Q plot provides a visual assessment and should be used in conjunction with other methods for a comprehensive analysis of normality.
5) Statistical Test
Shapiro-Wilk Test
The Shapiro-Wilk test is widely used for testing normality. This test checks the null hypothesis that the data were drawn from a normal distribution.
It is generally preferred for small sample sizes (< 50 samples), but can be used for larger ones.
shapiro.test(penguins$body_mass_g)
Shapiro-Wilk normality test
data: penguins$body_mass_g
W = 0.95921, p-value = 3.679e-08
Kolmogorov-Smirnov Test (K-S Test)
The K-S test compares the empirical distribution function of the data with the expected distribution function for a normal distribution.
This test is more sensitive towards the center of the distribution than the tails.
Asymptotic one-sample Kolmogorov-Smirnov test
data: standardized_data
D = 0.10408, p-value = 0.00121
alternative hypothesis: two-sided
Anderson-Darling Test
Similar to the K-S test, the Anderson-Darling test is a test of goodness of fit.
This test gives more weight to the tails than the K-S test and is thus more sensitive to outliers.
library(nortest)ad.test(penguins$body_mass_g)
Anderson-Darling normality test
data: penguins$body_mass_g
A = 4.543, p-value = 2.757e-11
Lilliefors Test
A modification of the K-S test, the Lilliefors test is specifically designed for testing normality.
It is particularly useful when the mean and variance of the distribution are unknown.
library(nortest)lillie.test(penguins$body_mass_g)
Lilliefors (Kolmogorov-Smirnov) normality test
data: penguins$body_mass_g
D = 0.10408, p-value = 1.544e-09
Basic Statistical Summarisation
Data summarization is a crucial aspect of statistical analysis, providing a way to describe and understand large datasets through a few summary statistics. Among the key concepts in data summarization are measures of central tendency, position, and dispersion. Each of these measures gives different insights into the nature of the data. [for continuous/numerical data only]
1. Measures of Central Tendency
Measures of central tendency describe the center point or typical value of a dataset. The most common measures are:
Mean (Arithmetic Average): The sum of all values divided by the number of values. It’s sensitive to outliers and can be skewed by them.
# calculating mean of numerical variablemean(penguins$body_mass_g, na.rm =TRUE)
[1] 4201.754
Median: The middle value when the data is sorted in ascending order. It’s less affected by outliers and skewness and provides a better central value for skewed distributions.
#calculating median of numerical variablemedian(penguins$body_mass_g, na.rm=TRUE)
[1] 4050
Mode: The most frequently occurring value in the dataset. There can be more than one mode in a dataset (bimodal, multimodal). Useful in understanding the most common value, especially for categorical data.
Measures of position describe how data points fall in relation to the distribution or to each other. These include:
Percentiles: Values below which a certain percentage of the data falls. For example, the 25th percentile (or 1st quartile) is the value below which 25% of the data lies.
quantile(penguins$body_mass_g, na.rm=TRUE)
0% 25% 50% 75% 100%
2700 3550 4050 4750 6300
Quartiles: Special percentiles that divide the dataset into four equal parts. The median is the second quartile.
Interquartile Range (IQR): The range between the first and third quartiles (25th and 75th percentiles). It represents the middle 50% of the data and is a measure of variability that’s not influenced by outliers.
IQR(penguins$body_mass_g, na.rm=TRUE)
[1] 1200
3. Measures of Dispersion
Measures of dispersion or variability tell us about the spread of the data points in a dataset:
min: To find the minimum value in the variable
min(penguins$body_mass_g, na.rm =TRUE)
[1] 2700
max: To find the maximum value in the variable
max(penguins$body_mass_g, na.rm=TRUE)
[1] 6300
length: to find how many observations in the variable
length(penguins$body_mass_g)
[1] 344
Range: The difference between the highest and lowest values. It’s simple but can be heavily influenced by outliers.
Variance: The average of the squared differences from the mean. It gives a sense of the spread of the data, but it’s not in the same unit as the data.
var(penguins$body_mass_g, na.rm=TRUE)
[1] 643131.1
Standard Deviation (SD): The square root of the variance. It’s in the same units as the data and describes how far data points tend to deviate from the mean.
sd(penguins$body_mass_g, na.rm=TRUE)
[1] 801.9545
Coefficient of Variation (CV): The ratio of the standard deviation to the mean. It’s a unitless measure of relative variability, useful for comparing variability across datasets with different units or means.
The summary() function in R is a generic function used to produce result summaries of various model and data objects. When applied to a data frame, it provides a quick overview of the statistical properties of each column. The function is particularly useful for getting a rapid sense of the data, especially during the initial stages of data analysis.
Key Features of summary() in R:
Applicability to Different Objects: The summary() function can be used on different types of objects in R, including vectors, data frames, and model objects. The output format varies depending on the type of object.
Default Output for Data Frames: For a data frame, summary() typically returns the following statistics for each column:
For factor variables: Counts for each level, and NA count if there are missing values.
Handling of Missing Values: The function includes NA values in its output, providing a count of missing values, which is crucial for data cleaning and preprocessing.
Customization: The behavior of summary() can be customized for user-defined classes (S3 or S4) in R. This means that when you create a new type of object, you can also define what summary() should return when applied to objects of this type.
Use in Exploratory Data Analysis (EDA): It is often used as a preliminary step in EDA to get a sense of the data distribution, identify possible outliers, and detect missing values.
summary(penguins)
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NA's :2 NA's :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
Median :197.0 Median :4050 NA's : 11 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NA's :2 NA's :2
Notes:
While summary() provides a quick and useful overview, it’s often just a starting point for data analysis. Depending on the results, you might need more detailed analysis, such as specific statistical tests or detailed data visualizations.
The function is particularly handy for quickly checking data after importation, allowing for a rapid assessment of data quality, structure, and potential areas that may require further investigation.
Data Summarization on Matrices
rowMeans(x):
Purpose: Calculates the mean of each row in a matrix x.
Use Case: Useful when you need to find the average across different variables (columns) for each observation (row).
Output: Returns a numeric vector containing the mean of each row.
data <- penguins# Selecting only numeric columns for the matrixnumeric_data <- data[, sapply(data, is.numeric)]numeric_matrix <-as.matrix(na.omit(numeric_data))# Apply summarization functions# Means of each rowrow_means <-rowMeans(numeric_matrix)
colMeans(x):
Purpose: Computes the mean of each column in a matrix x.
Use Case: Used when you want to find the average value of each variable (column) across all observations (rows).
Output: Produces a numeric vector with the mean of each column.
# Means of each columncolMeans(numeric_matrix)
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
43.92193 17.15117 200.91520 4201.75439
year
2008.02924
rowSums(x):
Purpose: Calculates the sum of each row in a matrix x.
Use Case: Helpful for aggregating data across multiple variables (columns) for each individual observation (row).
Output: Returns a numeric vector containing the sum of each row.
# Sums of each rowrow_sums <-rowSums(numeric_matrix)
colSums(x):
Purpose: Computes the sum of each column in a matrix x.
Use Case: Useful for aggregating data for each variable (column) across all observations (rows).
Output: Generates a numeric vector with the sum of each column.
# Sums of each columncolSums(numeric_matrix)
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
15021.3 5865.7 68713.0 1437000.0
year
686746.0
Detecting how many missing values
To detect how many missing values in the variable
table(is.na(penguins$body_mass_g))
FALSE TRUE
342 2
TRUE means number of missing values in the dataset for variable body_mass_g.
Detecting the missing value for the whole variables in the dataset
colSums(is.na(penguins))
species island bill_length_mm bill_depth_mm
0 0 2 2
flipper_length_mm body_mass_g sex year
2 2 11 0
Apply function
We can calculate summary statistics simultaneously by using sapply, this function allow us to get the numerical statistics measures for all numerical values. we will discuss about apply family in other lecture.
Mean
sapply(numeric_data, mean, na.rm=TRUE)
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
43.92193 17.15117 200.91520 4201.75439
year
2008.02907
Standard Deviation
sapply(numeric_data, sd, na.rm=TRUE)
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
5.4595837 1.9747932 14.0617137 801.9545357
year
0.8183559
Sum / total in a column
sapply(numeric_data, sum, na.rm=T)
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
15021.3 5865.7 68713.0 1437000.0
year
690762.0
Basically, we can just substitute the numerical measure inside the 2nd arguments.
Summary Statistics by group
Usually in data analysis, if there are a categorical variable, we would like to compare the numerical measure with the categorical data. For example, we want to know the mean and standard deviation by gender (male and female) instead of sumarizing the mean and standard deviation for whole dataset.
Example: calculating mean and standard deviation for mtcars dataset
#Testing the normality of Miles per Gallon variable by Number of cylinders#Selecing 4 cylinderscyl4 <- mtcars %>%filter(cyl==4)lillie.test(cyl4$mpg)
Lilliefors (Kolmogorov-Smirnov) normality test
data: cyl4$mpg
D = 0.16784, p-value = 0.5226
nbr.val nbr.null nbr.na min max range
3.420000e+02 0.000000e+00 2.000000e+00 3.210000e+01 5.960000e+01 2.750000e+01
sum median mean SE.mean CI.mean.0.95 var
1.502130e+04 4.445000e+01 4.392193e+01 2.952205e-01 5.806825e-01 2.980705e+01
std.dev coef.var
5.459584e+00 1.243020e-01
Summarizing categorical data is an essential part of data analysis, especially when dealing with survey results, demographic information, or any data where variables are qualitative rather than quantitative. The goal is to gain insights into the distribution of categories, identify patterns, and make inferences about the population being studied.
Key Concepts in Summarizing Categorical Data:
Frequency Counts:
The most basic form of summarization for categorical data is to count the number of occurrences of each category.
In R, table() function is commonly used for this purpose.
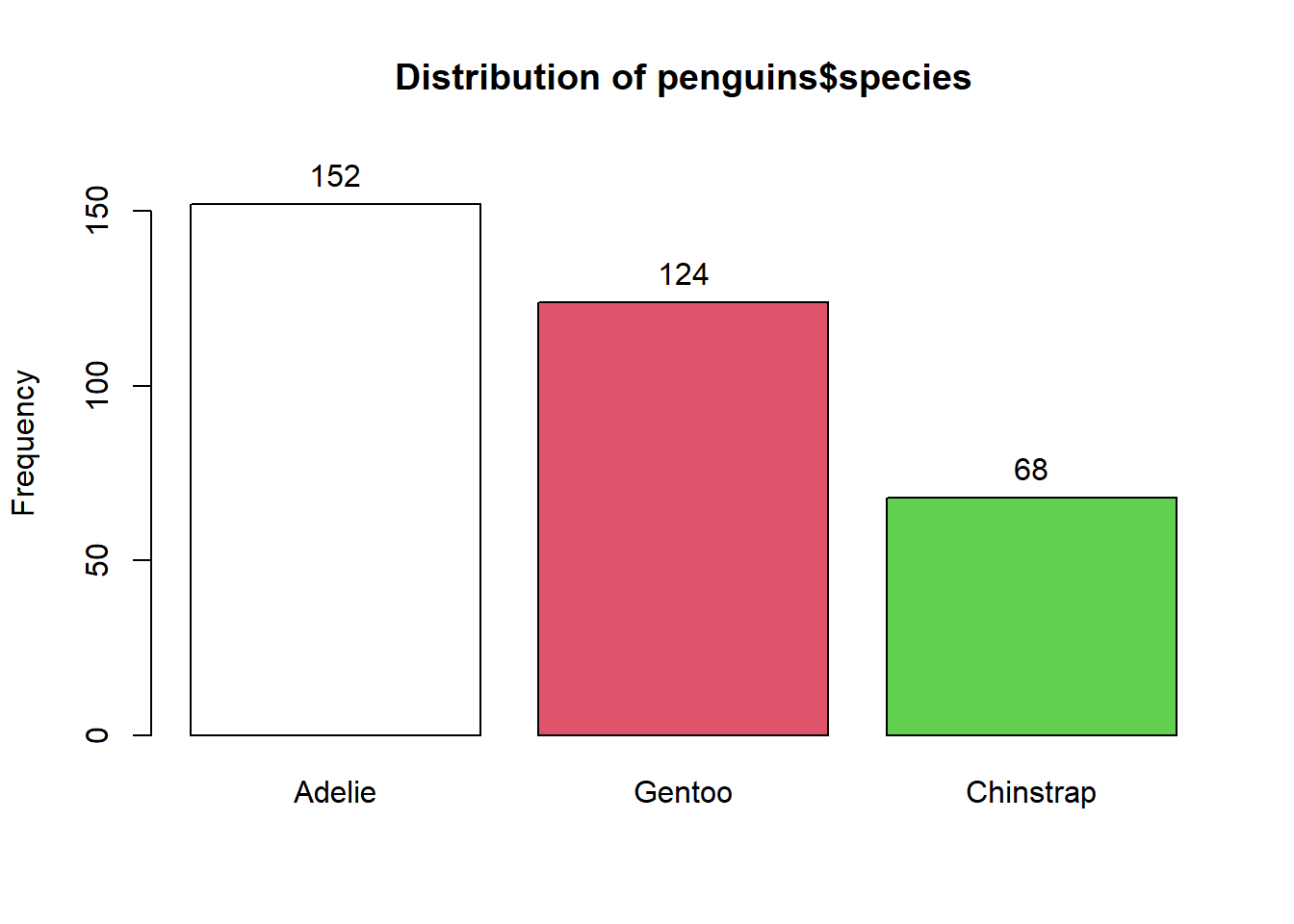
# To tabulate categorical datatable(penguins$species)
Adelie Chinstrap Gentoo
152 68 124
Proportions and Percentages:
Converting frequency counts into proportions or percentages provides a clearer understanding of the data relative to the whole.
This is particularly useful when comparing groups of different sizes.
#to get relative frequency by groupprop.table(table(penguins$species))
Cross-tabulation (or contingency tables) involves summarizing two or more categorical variables simultaneously, making it possible to observe the relationship between them.
In R, this can be achieved using the table() function with multiple variables.
# to tabulate the cross tabulation between species and islandtable(penguins$species, penguins$island)
This package can be also use for cross tabulation table, for example tabulation for species and sex
library(gmodels)CrossTable(penguins$species, penguins$sex,format="SPSS", expected = T, #expected valueprop.r = T, #row totalprop.c = F, #column totalprop.t = F, #overall totalprop.chisq = F, #chi-square contribution of each cellchisq = T, #the results of a chi-squarefisher = F, #the result of a Fisher Exact testmcnemar = F) #the result of McNemar test
# A tibble: 6 × 2
country before_2000_avg
<chr> <dbl>
1 Afghanistan 168
2 Albania 26.3
3 Algeria 41.8
4 American Samoa 8.5
5 Andorra 28.8
6 Angola 225.
new <- data1 %>% dplyr::select("country", "before_2000_avg")
4) Summarize the data by mean and standard deviation
summary(new)
country before_2000_avg
Length:208 Min. : 3.50
Class :character 1st Qu.: 26.45
Mode :character Median : 61.20
Mean :113.88
3rd Qu.:175.20
Max. :637.10
NA's :1
Youth Tobacco
Import the dataset from this link: https://dataintror.s3.ap-southeast-1.amazonaws.com/Youth_Tobacco_Survey_YTS_Data.csv
Frequencies
data2$MeasureDesc
Type: Character
Freq % Valid % Valid Cum. % Total % Total Cum.
--------------------------------------------------------------- ------ --------- -------------- --------- --------------
Percent of Current Smokers Who Want to Quit 1205 12.30 12.30 12.30 12.30
Quit Attempt in Past Year Among Current Cigarette Smokers 1041 10.63 22.93 10.63 22.93
Smoking Status 3783 38.63 61.56 38.63 61.56
User Status 3765 38.44 100.00 38.44 100.00
<NA> 0 0.00 100.00
Total 9794 100.00 100.00 100.00 100.00
summarytools::freq(data2$Gender)
Frequencies
data2$Gender
Type: Character
Freq % Valid % Valid Cum. % Total % Total Cum.
------------- ------ --------- -------------- --------- --------------
Female 3256 33.24 33.24 33.24 33.24
Male 3256 33.24 66.49 33.24 66.49
Overall 3282 33.51 100.00 33.51 100.00
<NA> 0 0.00 100.00
Total 9794 100.00 100.00 100.00 100.00
summarytools::freq(data2$Response)
Frequencies
data2$Response
Type: Character
Freq % Valid % Valid Cum. % Total % Total Cum.
-------------- ------ --------- -------------- --------- --------------
Current 2514 33.31 33.31 25.67 25.67
Ever 2520 33.39 66.69 25.73 51.40
Frequent 2514 33.31 100.00 25.67 77.07
<NA> 2246 22.93 100.00
Total 9794 100.00 100.00 100.00 100.00
2) Filter MeasureDesc = Smoking Status, all gender = overall and response = current year